dask.distributed - Parallel Processing in Python¶
Table of Contents¶
- Introduction
- Architecture of
dask.distributed - Setting Up
dask.distributedCluster - Example 1:
submit() - Example 2:
submit()with for loop - Example 3:
submit()with for loop and if-else condition - Example 4:
map() - Example 5:
gather() - Example 6:
scatter() - Example 7:
FutureInstance Methods & Attributes - Example 8:
as_completed() - Example 9:
wait() - Example 10:
fire_and_forget() - References
Introduction ¶
Dask is a very reliable and rich python framework providing a list of modules for performing parallel processing on different kinds of data structures as well as using different approaches. It provides modules like dask.bag, dask.dataframe, dask.delayed, dask.numpy, dask.distributed, etc. We have already covered dask.bag and dask.delayed as separate tutorials where we have given brief intro about dask and its other modules as well. We suggest that you go through our dask.bag introduction to get an idea about various dask modules. As a part of this tutorial, we'll be concentrating on dask.distributed module.
The dask.distributed module is wrapper around python concurrent.futures module and dask APIs. It provides almost the same API like that of python concurrent.futures module but dask can scale from a single computer to cluster of computers. It lets us submit any arbitrary python function to be run in parallel and return results once completed. The dask.delayed module also provides the same functionality as this with different API syntax but that module is lazy whereas this one is immediate. By dask.delayed being lazy, we mean that we can convert tasks to a delayed task using that module but they won't execute until we explicitly ask them to run it whereas in the case of dask.distributed, it'll start running the task as soon as you submit it to workers. We'll now explain the architecture of dask.distributed to better understand inner workings.
Architecture of dask.distributed ¶
The architecture of dask.distributed consists of below components which coordinates in order to run tasks in parallel.
Client------------ -----Worker-1
| |
Client ------ Scheduler --------Worker-2
| | |
Client ----------- | ----Worker-3
|
-------Worker-4
- Clients: They are responsible for submitting tasks to run in parallel to the scheduler. We can create a client instance by giving the address of the scheduler and submit tasks to the worker using this instance.
- Scheduler: One machine runs scheduler which is responsible for coordinating with both clients and workers for running tasks in parallel. It runs asynchronously accepting tasks concurrently from multiple clients and keeping track of the progress of work completed by workers. It keeps track of all tasks submitted to it as a directed acyclic graph which expands as more tasks as added and shrinks as tasks complete.
- Workers: They actually run tasks submitted to them by a scheduler. The workers do communicate with each other in order to share data.
This ends our small intro of dask.distributed. We'll first set up the dask cluster before starting with the coding task. We have explained 2 ways of setting it up below.
Setting Up dask.distributed Cluster ¶
We first need to set up dask.distributed in order to submit tasks to the scheduler to be run on workers. There are two ways to set up on a local computer.
1st Way: Commonly Used When Running Tasks on Single Computer¶
The way of setting up dask.distributed is a simple one where we just need to create client instance by calling Client class from dask.distributed. It'll internally create a dask scheduler and dask workers on local for us. It'll return the link of the dashboard as well which can be useful to analyze tasks running in parallel. We can consider client instance of dask same as ThreadPoolExecutor/ProccessPoolExecutor of concurrent.futures.
We can pass it a number of workers to create using n_workers and threads to use per worker process using threads_per_worker.
from dask.distributed import Client
client = Client(n_workers=4, threads_per_worker=4)
client
When using the above-mentioned way, the client starts dask with all workers running as separate processes with all of them having 4 threads. If we are running dask on a single PC and only wants to run threads in parallel instead of processes then we can create client object as given below. It'll create only one worker with 4 threads which will be run for running tasks in parallel.
client = Client(processes=False)
client
The warning you see after running the above command is because port 8787 which is the default for running dask scheduler has already one scheduler running. It'll use a different port for it after giving a warning.
Please make a note that if you want to analyze running tasks and directed acyclic graph generated for tasks using dashboard started with client instance then you'll need python visualization library bokeh installed. The dashboard is designed in bokeh.
2nd Way: Commonly Used When Running Tasks on Cluster of Computers¶
Another way to set up dask.distributed is to separately create dask schedulers and workers from the shell. We then create client instance by setting the IP and port of that scheduler to it. Below we have explained step by step process for setting up dask.distributed.
- 1. Start Scheduler by executing below command in the shell.
dask-scheduler
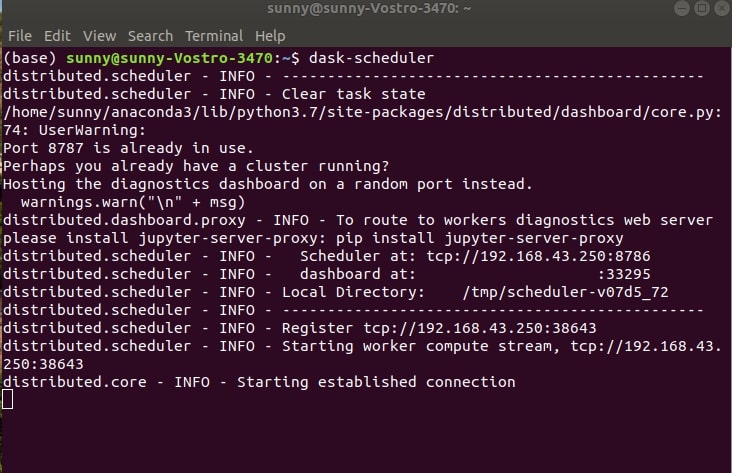
We need to keep this scheduler instance running for taking requests from the client to run tasks in parallel using workers created in the next steps.
There is a warning when starting the scheduler in the above screenshot because I have already running scheduler and workers created from 1st way of setting up dask.distributed. The warning suggests that port 8787 already has scheduler running hence it starts scheduler on port 8786. You won't face it if you use only one this way to set up dask.distributed.
- 2. Start workers by executing below commands in separate shells. We need to execute it in a number of shells as many workers we need to create. So if we want to create 4 workers then we need to execute it in 4 different shells and keep it running. Each will create a task.
dask-worker IP:port
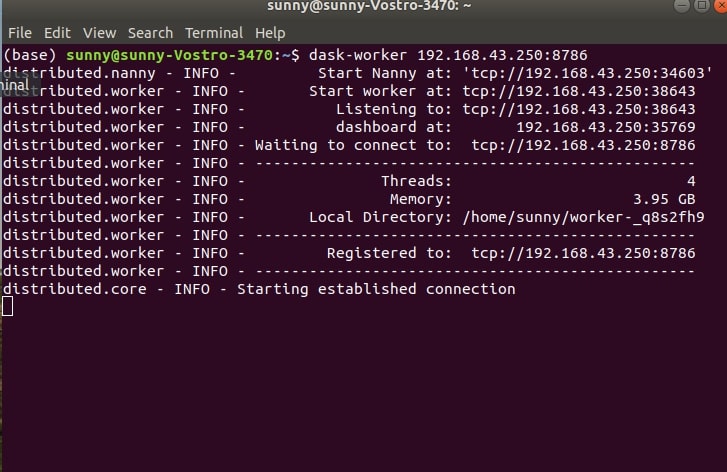
We need to pass the same IP address and port number where the scheduler is running. We need to keep these workers running in order to execute tasks in parallel.
- 3. Create client instance by passing it IP and port of the scheduler. We can then use this client instance to submit tasks to workers through the scheduler.
client = Client('192.168.43.250:8786')
The above-mentioned way is commonly be used to set up dask.distributed when you have schedulers, workers, and clients running on different PCs (Example: Google Cloud, AWS, or any other cloud service which lets users create a cluster of the computer). We can create scheduler & workers on a cluster in the cloud and then can submit tasks to it by creating client objects on local by connecting to the scheduler using IP and Port. We can even submit tasks from a computer that is running a dask scheduler in the cloud by logging to it using SSH from local.
Please make a note that you see above my IP address because I am connected to Internet. If you are not connected to Internet and start scheduler from command line then you'll see IP address as 127.0.0.1.
As we have our dask cluster ready to accept tasks running in parallel. We'll now start with the actual coding part where we'll be submitting various functions to run in parallel on dask workers. We'll also explore dask.distributed API to explain various functions available through it.
We'll now start by explaining various methods of dask.distributed API which will let us run the task in parallel on dask workers.
Example 1: submit() ¶
The simplest way to run tasks on workers is by calling submit() method on client object, passing it function and list of parameters function requires. As soon as we call submit() method on client object passing it function and function arguments, it starts running returning Future instance object. This is the reason dask.distributed API is called immediate because it starts execution immediately and dask.delayed is called lazy because it starts execution only when explicitly asked to compute results. This Future instance has information about task status and task results.
We suggest that you go through our tutorial on dask.delayed as well to better understand both dask.distributed and dask.delayed APIs.
import time
def slow_pow(x,y):
time.sleep(1)
return x ** y
res = client.submit(slow_pow, 10,10)
res
We can notice that when we printed future instance the first time, its status is shown as pending. We'll now call it again to see its status. We can call result() method on future instance once task running on the worker to which future is pointing completes successfully.
res
res.result()
Please make a note that we'll be using %%time and %time jupyter notebook magic commands to measure execution of particular code section. It'll be used for performance comparison between normal python and dask parallelized python code.
Example 2: submit() with for loop ¶
Below we are explaining another example of submitting list of tasks to dask workers.
The first we have designed code which runs sequentially without using any parallelism and then we'll convert the same code to run in parallel using dask.
Below code loops from 1 to 10 calling slow_pow() function each time passing it a number and power value of 10. It tries to get the power of 10 for each number. It runs sequentially hence takes 10 seconds to complete.
%%time
powers_of_10 = []
for i in range(1,11):
res = slow_pow(i,10)
powers_of_10.append(res)
powers_of_10
Below we have converted the same code written above to run in parallel. We have submitted each function call to slow_pow() to dask workers by passing it to submit() method of client. We are also maintaining a list of future instances returned by each call to submit().
We then loop through future instances calling result() method on each to get the result of function execution. We can notice that it takes nearly 1-2 seconds to complete running things in parallel which is quite fast compared to a sequential run from the previous step.
%%time
powers_of_10 = []
for i in range(1,11):
future = client.submit(slow_pow,i,10)
powers_of_10.append(future)
[future.result() for future in powers_of_10]
Example 3: submit() with for loop and if-else condition ¶
Below we have designed anther function for explaining the usage of submit() function. We are again using for-loop same as last time but have introduced if-else condition where we call a different function when the number is even and different when it’s odd.
We are looping through number 1 to 10 each time calling slow_pow() if number is even and slow_add() if number is odd. We raise the number to the power of 2 if it’s even and adds 1 to it if it’s odd.
We have the first run the function sequentially and then converted the same code to run in parallel.
def slow_add(x,y):
time.sleep(1)
return x + y
%%time
powers = []
for i in range(1,11):
if i%2 == 0:
res = slow_pow(i,2)
else:
res = slow_add(i,1)
powers.append(res)
powers
%%time
powers = []
for i in range(1,11):
if i%2 == 0:
future = client.submit(slow_pow, i, 2)
else:
future = client.submit(slow_add, i, 1)
powers.append(future)
[future.result() for future in powers]
Example 4: map() ¶
The dask.distributed API provides map() which has exact same functionality as that of core python but it can run things in parallel on dask workers.
Below we have explained usage of map() by calling slow_add() function with different arguments. The map() also returns a list of future instances once tasks as submitted to workers. We can later call result() method on these instances to get the result of function execution.
%%time
futures = client.map(slow_pow, [1,2,3,4,5], [10]*5)
[future.result() for future in futures]
%%time
futures = client.map(slow_add, [1,2,3,4,5], [5,4,3,2,1])
[future.result() for future in futures]
Example 5: gather() ¶
The gather() method provided by dask.distibuted API accepts a list of futures instances as input and returns the result of the execution of these future instances. We can use this method to retrieve the result of the execution of a list of futures instances. Till now, We were explicitly calling result() method on the future instances to get the result of future execution by looping through each future. We can accomplish the same using gather() method.
Below we have explained the usage of gather() method.
%%time
futures = []
for i in range(1,11):
future = client.submit(slow_pow, i, 5)
futures.append(future)
client.gather(futures)
%%time
powers = []
for i in range(1,11):
if i%2 == 0:
future = client.submit(slow_pow, i, 2)
else:
future = client.submit(slow_add, i, 1)
powers.append(future)
client.gather(powers)
Example 6: scatter() ¶
The scatter() method provided by dask.distributed API lets us scatter data on various workers. This method can be useful when data required by methods to work is huge and passing data between workers can take a lot of time. We can use this method beforehand which will distribute data to various workers. We have explained its usage below with an example.
data_futures = client.scatter([1,2,3,4,5,6,7,8])
data_futures
%%time
task_futures = []
for i in range(0,8,2):
res = client.submit(slow_add, data_futures[i], data_futures[i+1])
task_futures.append(res)
client.gather(task_futures)
Example 7: Future Instance Methods & Attributes ¶
The Future instance returned by previous methods once a task is submitted to the worker provides a list of useful methods that can provide useful information about tasks running on the worker. Below we are a list of useful methods and attributes provided by Future instance:
- status: It returns the status of task execution which can be
pending, finished, error, canceled, etc. - done(): It returns
Trueif task has completed asFalse. - cancel(): It can cancel the task running on the worker.
- cancelled(): It returns
Trueif task is cancelled elseFalse. - exception(): It returns an error explaining exception happened during the execution of task if any else it returns
None. - traceback(): It returns traceback details if task execution fails else returns
None. - retry(): It reruns task again.
- release(): It releases dask worker. When this method is called future instance stops pointing to dask workers hence results will be lost. Please use it with caution and call it only when you are sure that the task has completed and you have gathered results.
res = client.submit(slow_pow, 10,10)
res
Check Status of Task¶
We can check the status of a task by calling status attribute to check whether the task has completed or not.
res.status
res.done()
Cancel Task¶
We can cancel the task as well by using the cancel() method if it’s taking too long and we want to terminate it for some other reason. If we try to call result() method on a cancelled task then it'll raise an exception.
res.cancel()
res.cancelled()
res.result()
Task With Errors¶
res = client.submit(slow_pow, 10, "0.5")
res
res
res.exception()
trace = res.traceback()
trace.tb_frame
Retry Tasks¶
Below we are retrying the same task as above which had failed to check whether it runs successfully this time.
res.retry()
res
Release Future¶
We can release future instances by calling the release() method on it which will end the link between dask worker and future instance. If we release the future when the task is running then it'll be canceled.
res = client.submit(slow_pow, 10, 5)
res
res.result()
res.release()
Example 8: as_completed() ¶
The dask.distributed provides as_completed() which has the same usage as the method available with the same name in concurrent.futures. It accepts a list of future instances and returns future instances that have completed one by one. The as_completed() method returns iterator looping through which returns future instances which have completed.
Below we have explained the usage of as_completed() method by comparing it with normal dask parallel execution.
Please make a note that results won't be returned in the same sequence as the one in which tasks were submitted to workers. It'll return future instance when task associated it with completes running on dask worker. This can results in different sequence than the one in which tasks were submitted. We have explained it below with example.
%%time
futures = []
for i in range(1,31):
if i%2 == 0:
res = client.submit(slow_pow, i,2)
else:
res = client.submit(slow_pow, i,3)
futures.append(res)
[future.result() for future in futures][:10]
from dask.distributed import as_completed
%%time
futures = []
for i in range(1,31):
if i%2 == 0:
res = client.submit(slow_pow, i,2)
else:
res = client.submit(slow_pow, i,5)
futures.append(res)
[future.result() for future in as_completed(futures)][:10]
Example 9: wait() ¶
The wait() method accepts a list of future instances like as_completed() method but it'll prevent any further line after it from executing until all tasks have completed executing. It returns a dictionary-like object called DoneAndNotDoneFutures which has information about future instances which completed successfully and which do not.
Below we have explained its usage by comparing it with normal dask execution which maintains a sequence of execution. The wait() method like as_completed() does not return future instances in the same sequence in which they were submitted hence results can be in a different sequences.
%%time
futures = []
for i in range(1,11):
res = client.submit(slow_pow, 1, 10)
futures.append(res)
futures
from dask.distributed import wait
%%time
futures = []
for i in range(1,11):
res = client.submit(slow_pow, i, 2)
futures.append(res)
result_dict = wait(futures, return_when="ALL_COMPLETED")
result_dict
[future.result() for future in result_dict.done][:10]
Example 10: fire_and_forget() ¶
It many times happens that we want a particular task to complete execution in the background without we expecting any kind of results from it. We might not keep track of future instances in that case. The dask stops workers to which it does not find any future instance pointing to it which might be running tasks. We want to make sure that even though we are not maintaining future instances for tasks submitted to the worker, it completes successfully.
We might need this kind of functionality when we want to save files in between processing or at the end of processing. We just want tasks to complete by saving files but we don't want any results from it. We can use the fire_and_forget() method for this kind of task.
We can call fire_and_forget() passing it future instance and it'll keep that task running on worker until it completes even though we have lost future pointing to it.
We have below designed an example explaining the usage of the fire_and_forget() method. We loop through 30 days of the month and create a pandas dataframe with temperature captured every one hour for that day. We are creating a dataframe for each day and then saving that dataframe as CSV file to disk. We want that when we submit a task to the worker to save a file, it completes successfully even if we do not maintain future instances pointing to it because we don't want to retrieve any kind of result from its completion.
from dask.distributed import fire_and_forget
import numpy as np
import pandas as pd
for i in range(1, 31):
data = np.random.randint(1,50, 24).reshape(24,1)
time_stamps = pd.date_range(start="2020-1-%d"%i,end="2020-1-%d"%(i+1), freq="H")[:-1]
df = pd.DataFrame(data, index=time_stamps, columns=["Temperature"])
res = client.submit(df.to_csv, "Day %d.csv"%i)
fire_and_forget(res)
This ends our small tutorial on dask.distributed API of dask which is almost same as concurrent.futures API. Please let us know your views in the comments section.
References ¶
Below is a list of other python libraries providing parallel processing APIs.
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![YouTube Subscribe]() Comfortable Learning through Video Tutorials?
Comfortable Learning through Video Tutorials?
If you are more comfortable learning through video tutorials then we would recommend that you subscribe to our YouTube channel.
![Need Help]() Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
 Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?
Stuck Somewhere? Need Help with Coding? Have Doubts About the Topic/Code?When going through coding examples, it's quite common to have doubts and errors.
If you have doubts about some code examples or are stuck somewhere when trying our code, send us an email at coderzcolumn07@gmail.com. We'll help you or point you in the direction where you can find a solution to your problem.
You can even send us a mail if you are trying something new and need guidance regarding coding. We'll try to respond as soon as possible.
![Share Views]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 dask, parallel-computing
dask, parallel-computing