
GLUE Benchmark Explained¶
A few years ago, the concept of transfer learning was alien to natural language models. It was mainly confined to only computer vision models where it was quite prevalent. NLP models were trained for one particular task and were evaluated for the same. There was no scope for reusing the trained model for any other task.
But over the years, big tech has extended their research in this area and made transfer learning possible for NLP models. It happened with the rise of Transformer architecture which paved the way for large language models (LLMs).
With the advent of LLMs, it became possible to use one single model for multiple tasks. LLMs are first trained on a large corpus of data (pre-training) to understand it. The common task in this case is to predict the next word in a sentence. Once the model is good at this task, it is believed that it has understood training data well. Then, this pre-trained model can be used for many other NLP tasks (commonly referred to as downstream tasks) like translation, sentiment analysis, NER, text classification, text generation, etc. The model prepared after the training stage is fine-tuned and can perform all of these tasks. LLMs made transfer learning possible for NLP tasks.
Now, with transfer learning in NLP, it is possible to use the same Language Model for multiple tasks. Hence, the old way of evaluating model performance on a single task is insufficient. A different way was needed to evaluate such LLMs on all tasks to find out whether the model understood natural language better or not.
This need gave rise to the General Language Understanding Evaluation (GLUE) benchmark. The team at NYU, Univ of Washington, and other tech companies put together nine datasets (for nine NLU tasks) for evaluating Natural Language Understanding systems (which we commonly refer to as LLMs sometimes). The datasets are selected by expert researchers in the field. The website is also created for GLUE which maintains datasets and a leaderboard of the performance of various models submitted for evaluation on these nine tasks. The website also provides a starter code for submitting model performance on various tasks. The average score of model on all nine tasks is used to rank it on the leaderboard. The nine datasets evaluate models from different perspectives and help us understand how good model understands natural language.
GLUE Tasks¶
Now, let me introduce you to nine tasks for which datasets are provided.
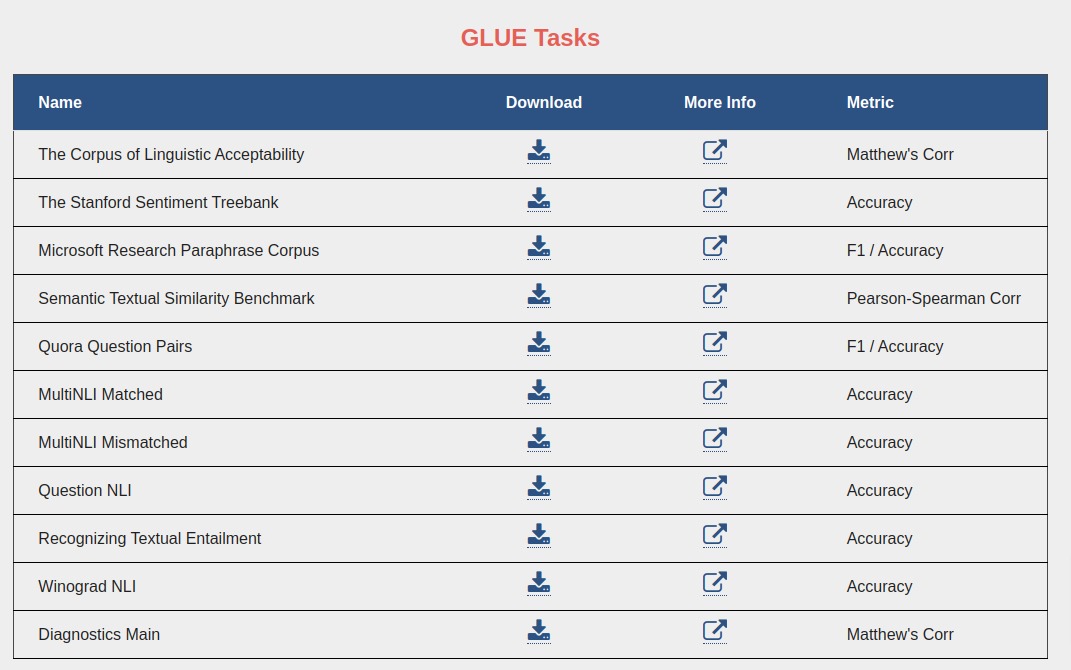
Single Sentence Tasks
- COLA (Corpus of Linguistic Acceptability) - The dataset has a list of English sentences drawn from books & journals and the task is a classification task of whether the sentence is a grammatical English sentence or not. The labels range from -1 to 1, with 0 being an uninformed guess. The evaluation metric on the dataset is Matthew’s correlation.
- SST-2 (Stanford Sentiment Treebank) - The dataset has movie reviews and labels are human sentiment. It’s a sentiment prediction task. The evaluation metric is accuracy.
Similarity and Paraphrase Tasks
- MRPC (Microsoft Research Paraphrase Corpus) - The dataset has a list of sentence pairs collected from online news sources. The task is to predict whether sentence pair is semantically equivalent. The evaluation metrics are F1-score and accuracy.
- QQP (Quora Question Pairs) - The dataset has a list of question pairs collected from Quora. The task is to determine whether the question pair is semantically equivalent. The evaluation metrics are F1-score and accuracy.
- STS-B (Semantic Textual Similarity Benchmark) - The dataset is a collection of sentence pairs retrieved from news headlines, videos & image captions, and NLI data. The task is to predict similarity which is in the range of 1-5 for the sentence pair. The evaluation metric is Pearson and Spearman Correlation Coefficients.
Inference Tasks
- MNLI (Multi-Genre Natural Language Inference Corpus) - The dataset is a collection of sentence pairs. One of the sentences in a pair is a premise sentence and another is a hypothesis sentence. The task is to predict whether the premise entails hypothesis (entailment), contradicts hypothesis (contradiction), or neither (neutral). The evaluation metric is accuracy.
- QNLI (Stanford Question Answering Dataset) - It is a question-answering dataset consisting of question-paragraph pairs. One of the sentences from the paragraph has an answer to the question. The original task is converted into sentence pair classification by forming a pair between the question and each sentence of the paragraph. The task is to determine whether a sentence contains an answer to the question. The evaluation metric is accuracy.
- RTE (Recognizing Textual Entailment) - The dataset is collected from a series of annual textual entailment challenges. It is the same task as MNLI with the only difference being that contradiction and neutral labels are combined into a new label no_entailment. The evaluation metric is accuracy.
- WNLI (Winograd Schema Challenge) - It is a reading comprehension task where the system must read a sentence with a pronoun and find out the referent of that pronoun from a list of choices. The original comprehension task is converted into a sentence pair classification task by replacing ambiguous pronouns with each possible referent. The task is to predict whether an original sentence entails a sentence with a pronoun replaced. The evaluation metric is accuracy.
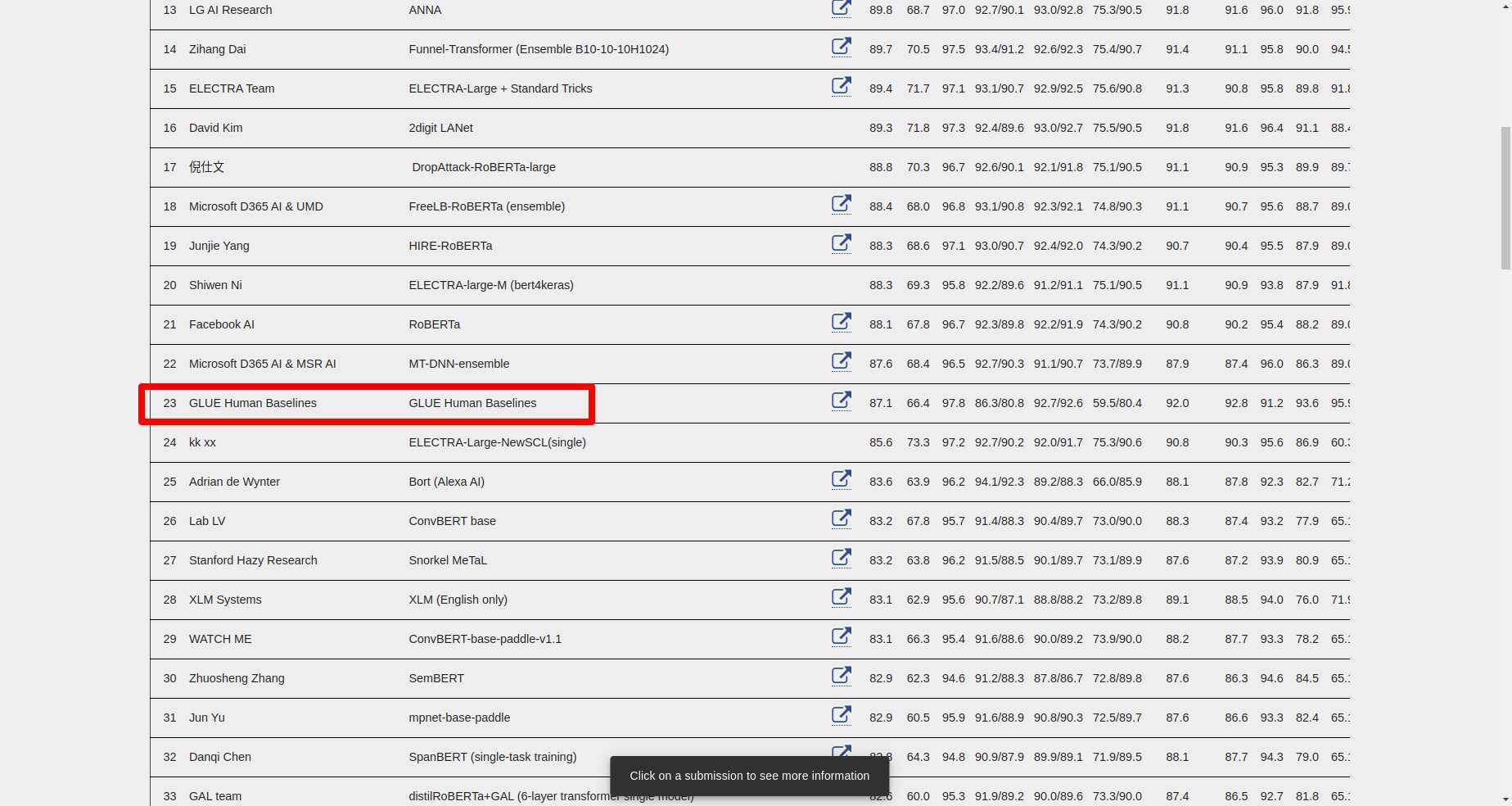
The score is calculated on these 9 tasks and then an average score is calculated to rank the model on the leaderboard.
Apart from models, there is also human evaluation ranked on the leader board where the performance of human is evaluated on these tasks. Currently, many models have passed
To test your model with various tasks from GLUE, you need to modify the model’s input and output so that they can handle each task. For tasks requiring double sentences as input need model modification for handling that case. The output layer too needs to be added for each task.
That was a small introduction to the GLUE benchmark. Feel free to explore other blogs on our website.
References¶
 Sunny Solanki
Sunny Solanki
Sunny Solanki
Intro: Software Developer | Youtuber | Bonsai Enthusiast
About: Sunny Solanki holds a bachelor's degree in Information Technology (2006-2010) from L.D. College of Engineering. Post completion of his graduation, he has 8.5+ years of experience (2011-2019) in the IT Industry (TCS). His IT experience involves working on Python & Java Projects with US/Canada banking clients. Since 2020, he’s primarily concentrating on growing CoderzColumn.
His main areas of interest are AI, Machine Learning, Data Visualization, and Concurrent Programming. He has good hands-on with Python and its ecosystem libraries.
Apart from his tech life, he prefers reading biographies and autobiographies. And yes, he spends his leisure time taking care of his plants and a few pre-Bonsai trees.
Contact: sunny.2309@yahoo.in



![]() Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?
 Want to Share Your Views? Have Any Suggestions?
Want to Share Your Views? Have Any Suggestions?If you want to
- provide some suggestions on topic
- share your views
- include some details in tutorial
- suggest some new topics on which we should create tutorials/blogs
 GLUE-Benchmark, LLM-Evaluation
GLUE-Benchmark, LLM-Evaluation